Arras Session Definitions
Arras clients use a session definition when creating a new session, to describe the computations that should be created. This is an example session:
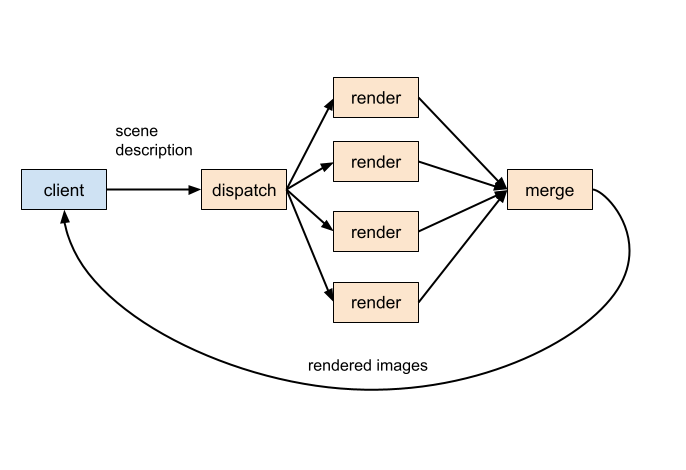
The definition for this session is essentially a JSON document describing the diagram. In outline, it looks like this:
{
"name": "multi-render",
"computations": {
"(client)": { ... },
"dispatch": { ... },
"mcrt": {
"arrayExpand": 4, ...
},
"merge": { ... }
}
}
name is mainly for documentation, and has no effect of the meaning of the definition.
(client) is used to specify message connections for the session client, which isn’t actually a computation. The names of the remaining computations are arbitrary, as long as they are unique within the session. However, sometimes client applications that load and manipulate session definition files will expect certain names to be used.
Only one entry is needed for the four mcrt computations : the arrayExpand field causes Arras to duplicate this computation four times.
Inside each computation block are parameters pertaining to that computation. Some of these are general and used with every computation type, others are specific. The most important of the parameters is dso, providing the name of the shared library that implements the computation’s logic:
"(client)": { ... },
"dispatch": {
"dso": "libcomputation_progmcrt_dispatch.so",...
},
"mcrt": {
"dso": "libcomputation_progmcrt.so",
"arrayExpand": 4, ...
},
"merge": {
"dso": "libcomputation_progmcrt_merge.so",...
}
The dsos shown here are part of the MoonRay release. Another general parameter is entry, which should appear in just one computation. Arras will use whichever machine is assigned to this computation as the entry node – meaning that this is the machine that the client will connect to, to communicate with the session. It is not required, but the session may be slightly more efficient if the entry computation is one that communicates directly with the client. In this case, we pick the dispatch computation:
"dispatch": {
"dso": "libcomputation_progmcrt_dispatch.so",
"entry":"yes",...
},
One of the parameters specific to the MoonRay computations is fps, which says how many times per second the session should snapshot the current render progress and send it back to the client. If fps is set too low, then visual feedback to the application user may suffer. In principle, if it is set too high, returning image messages might overload network bandwidth to the client. However, in practice, the nature of the encoding used for rendered images means that the required bandwidth is roughly the same over a broad range of fps values. fps should be specified for all computations (merge, mcrt and dispatch) in a multi-machine render.
"dispatch": {
"dso": "libcomputation_progmcrt_dispatch.so",
"entry":"yes",
"fps":1
},
Each of the computations also needs to know the number of mcrt computations in the session. Rather than specify this directly, we can use the array variable $arrayNumber.mcrt, which evaluates to the number of computations in the render array (4, in this case). Doing it this way means that we only have to modify one parameter (“mcrt”/”arrayExpand”) to change the session size. Each of the mcrt computations also needs to know its own index in the array, which is provided by the variable $arrayIndex.
"dispatch": {
...
"numMachines":"$arrayNumber.mcrt",...
},
"mcrt": {
...
"arrayExpand": 4,
"numMachines": "$arrayNumber",
"machineId": "$arrayIndex, ...
},
"merge": {
...
"numMachines":"$arrayNumber.mcrt",...
}
The name of these parameters is a bit misleading since, strictly speaking, they refer to the number of mcrt computations rather than the number of machines used. In practice, the session is usually set up so that each mcrt computation is placed on a different machine, since there is no advantage in splitting the cores on one machine between two or more different mcrt computations.
The MoonRay mcrt computations have a number of other optional parameters, listed in full at the end of this document.
Requirements
Another section in each computation block is used by the Coordinator service to decide how to allocate the computations to actual machines. The most important part of this is the number of CPU cores and the amount of memory required by each computation.
"mcrt": {
...
"requirements": {
"resources": {
"maxCores": "*",
"minCores": 1.0,
"memoryMB": 16384
}
},
These settings will only assign a mcrt computation to a machine that has at least 1 CPU core and 16384 Mb of memory remaining. Setting maxCores to ‘*’ causes Coordinator to give the mcrt computation all remaining cores on the machine it is assigned to.
We are not providing any resource specifications for the dispatch computations.
Also, we are not providing any resource specifications to the merge computations under small total mcrt computation cases.
They will get the default of exactly 1 core and 16384 Mb of memory.
It would be better to assign more than 1 core to the merge computation depending on the total mcrt computation count.
To specify an exact number of cores explicitly, use the parameter cores in place of maxCores and minCores.
Coordinator will always allocate all computations with a fixed cores requirement before allocating those with a min/max range. In practice this rule, together with the requirements just discussed, means that each machine can only host one mcrt computation, but the merge and dispatch computations can be placed on any of the mcrt computation machines.
The number of cores that Coordinator assigns to a mcrt computation determines the number of threads that MoonRay will use for rendering. If CPU cores are oversubscribed by the total number of MoonRay threads on the machine, then rendering may lose efficiency. For this reason, the total assigned core count is enforced by Arras and by the MoonRay computations.
It is currently quite difficult to predict the total amount of RAM that will be used by a render, and there isn’t really a useful way to constrain it to be within fixed limits. Although Coordinator will not oversubscribe memory on a machine – according to the usage listed in the “requirements” section of the session definition – actual memory usage by MoonRay is not, by default, constrained to be within these limits. In other words, the mcrt computation will use as much memory as it needs, regardless of what is listed in the session definition. Therefore it is not critical to set the “memoryMB” value in “requirements” accurately : especially if the CPU core settings prevent multiple mcrt computations on the same machine. The Arras Node implementation is capable of enforcing computation memory constraints, using cgroups, but this is not a mechanism that we have enabled in production use.
Another part of the requirements section describes the software environment required to run the computations.
"mcrt": {
...
"requirements": {
"computationAPI": "4.x",
"packaging_system": "current-environment",...
}
}
computationAPI is the version of Arras required to run the computation, and should always be “4.x”.
Arras is written to support software versioned using the Rez system. When Rez is being used, packaging_system would be set to “rez”, and additional parameters in the requirements section would specify the Rez packages needed. Setting packaging_system to “current-environment” is simpler, and causes the computation to run in the same environment that the Node launching the computation was started in. Session definitions may also use the parameter context, which refers to a complex environment attached to the definition in a separate section. Since these methods are quite specific to the software versioning systems used at DWA, they are not discussed further here.
Messages
The messages sections describe the messaging connections between computations – the arrows in the diagram at the beginning of this section. Each computation describes the types of messages that it wants to receive from other computations.
The client wants to receive all messages sent by the merge computation:
"(client)": {
...,
"messages": {
"merge": "*"
}
}
Dispatch receives RDLMessages containing scene data and forwards them to the mcrt computations. It also handles GenericMessage for debugging support and JSONMessage to support picking:
"dispatch": {
...,
"messages": {
"(client)": {
"accept": [
"RDLMessage",
"GenericMessage",
"JSONMessage"
]
}
}
}
In the (client) message section, “*” is shorthand for “accept”: [ “*” ]. The messages section can also contain an “ignore” list, but this is never used in practice.
"mcrt": {
...,
"messages": {
"(client)": {
"accept": [
"GenericMessage",
"ViewportMessage"
]
},
"dispatch": "*",
}
}
GenericMessage is used for debugging. ViewportMessages are sent by the client to modify the render viewport : all of the mcrt computations receive these.
"merge": {
...,
"messages": {
"(client)": {
"accept": [
"ViewportMessage",
"GenericMessage"
]
},
"mcrt": {
"accept": [
"ProgressiveFrame",
"GenericMessage",
"JSONMessage"
]
},
}
}
ProgressiveFrame is render result that can be produced by the mcrt computations.
Credit Messages
Credit messages are sent by the client to limit the rate at which mcrt and merge computations output render snapshot frames. If this rate exceeds the rate at which they can be transmitted by the network or processed by the client, messages will accumulate in intermediate buffers and cause ever-increasing latency. The progressive frame format is incremental, and means that Arras cannot safely drop messages even if it is overloaded. However it also means that the size of ProgressiveFrame messages decreases as they are sent more frequently. The overall bandwidth required tends to remain the same regardless of the snapshot frequency, within reasonable limits, so the credit mechanism is less critical than it has been in the past. It still can be useful to enable credit messages to protect against unusual network conditions.
Computations that receive credit messages need the parameter initialCredit set, and CreditUpdate added to their messages. Credit messages travel in the reverse direction to the rendered frames : in a multi-machine render, the client sends credit messages to merge and merge sends credit messages to the mcrt computations.
"merge" : {
...,
"sendCredit": true
"initialCredit": 2,
"messages": {
"(client)": {
"accept": [
"ViewportMessage",
"CreditUpdate"
]
},
...
}
},
"mcrt" : {
...,
"initialCredit":2,
"messages": {
...,
"merge": {
"accept": [
"CreditUpdate"
]
}
}
}
initialCredit = 2 means that these computations will only allow 2 progressive frame messages to be in the pipeline and not yet received and processed. The client code is responsible for explicitly sending a CreditUpdate message when it has received and processed each frame.
Session definition files
Session definitions are usually written as a JSON template file loaded by the client. After loading, the client modifies any fields in the template that are configurable. The most common modification is to the arrayExpand field in a multi-machine render. The client code can obtain information from the user on how many render machines are desired, and place that value in arrayExpand. fps is another commonly modified field.
Session definitions files have the extension “.sessiondef”
Complete session definitions
Single machine render with credit
{
"name": "single_credit",
"computations": {
"(client)": {
"messages": {
"mcrt": "*"
}
},
"mcrt": {
"dso": "libmcrt_computation_progmcrt.so",
"entry": "yes",
"fps": 1,
"initialCredit": 2,
"requirements": {
"computationAPI": "4.x",
"packaging_system":"current-environment",
"resources": {
"maxCores": "*",
"minCores": 1.0,
"memoryMB": 16384.0
}
},
"messages": {
"(client)": {
"accept": [
"RDLMessage",
"GenericMessage",
"ViewportMessage",
"JSONMessage",
"CreditUpdate"
]
}
}
}
}
}
Multi-machine render with credit
{
"name": "multi_credit",
"computations": {
"(client)": {
"messages": {
"merge": "*"
}
},
"dispatch": {
"dso": "libmcrt_computation_progmcrt_dispatch.so",
"entry": "yes",
"fps": 1,
"numMachines": "$arrayNumber.mcrt",
"requirements": {
"computationAPI": "4.x",
"packaging_system":"current-environment",
},
"messages": {
"(client)": {
"accept": [
"RDLMessage",
"GenericMessage",
"JSONMessage" ]
]
}
}
},
"mcrt": {
"arrayExpand": 4,
"dso": "libmcrt_computation_progmcrt.so",
"fps": 1,
"machineId": "$arrayIndex",
"numMachines": "$arrayNumber",
"initialCredit": 2,
"requirements": {
"computationAPI": "4.x",
"packaging_system":"current-environment",
"resources": {
"maxCores": "*",
"minCores": 1.0,
"memoryMB": 16384
}
},
"messages": {
"(client)": {
"accept": [
"GenericMessage",
"ViewportMessage"
]
},
"merge": {
"accept": [
"CreditUpdate"
]
},
"dispatch": "*"
}
},
"merge": {
"dso": "libmcrt_computation_progmcrt_merge.so",
"fps": 1,
"initialCredit": 2,
"sendCredit": true,
"numMachines": "$arrayNumber.mcrt",
"requirements": {
"computationAPI": "4.x",
"packaging_system":"current-environment"
},
"messages": {
"(client)": {
"accept": [
"ViewportMessage",
"CreditUpdate"
]
},
"mcrt": {
"accept": [
"PartialFrame",
"ProgressiveFrame",
"GenericMessage",
"JSONMessage"
]
}
}
}
}
}
Full list of MoonRay computation options
This is a full list of the options supported by each computation. Many are currently experimental.
Dispatch computation
| attribute | type | default | description |
|---|---|---|---|
| continuous | bool |
false | The dispatch computation sends a snapshot message downstream at the user-defined fps interval if the continuous command is set true. You should use set the mcrt computation option frameGating to true if the continuous option is set to true. This option is experimental. |
| fps | float |
12.0 | set image update frames-per-second |
MCRT computation
| attribute | type | default | description |
|---|---|---|---|
| applicationMode | string “motionCapture” |
undefined | Affects the behavior of the backend mcrt computation. Currently, we have one possible setting : “motionCapture”, but this is experimental. The default of “undefined” is best for interactive lighting sessions. |
| auto_affinity | string “on”|“off” |
“on” | Specify auto_affinity option (See here for more details). |
| cpu_affinity | string ”<cpuIdString>“ |
”” (empty) | Specify cpu_affinity option (See here for more details). |
| dsopath | string (path) |
”” (empty) | Prepend to search path for RDL DSOs. Same as moonray’s command-line option -dso_path. |
| enableDepthBuffer | bool |
false | This command generates pixel center depth value as pixelInfo data, independent from AOV buffers. A client can access pixelInfo value using the mcrt_dataio::ClientReceiverFb::getPixelInfo*() APIs. |
| exec_mode | string “auto”|“vector” |“scalar”|“xpu” |
auto | Choose a specific mode of execution. Same as moonray’s command-line option “-exec_mode”. |
| fastGeometry | bool |
false | If this flag is false, the tessellation related data for subdivision surfaces will be deleted after tessellation is done. Otherwise, that data will be kept in memory to support re-tessellation after geometry are updated. Same as SceneVariable’s “fast_geometry_update”. |
| fps | float |
12.0 | Set image update fps. |
| frameGating | bool |
false | In a multi-machine configuration, frame gating is handled upstream (i.e. dispatch computation) if this option is true, and receiving an update indicates it’s time to render the next frame. Receiving a snapshot-request indicates it’s time to make another snapshot. Under single-machine configuration, this command is just skipped. This option is experimental. |
| initialCredit | int |
-1 | Set initial credit rate for arras message passing layer. If rate is >= 0 credit rate control will be enabled otherwise it is inactive. |
| machineId | int |
-1 (default value does not work. You should always define machineId) | Each backend mcrt computation’s machineId. This machineId should be independent on each backend mcrt computations. Machine id should be start from 0 to the total number of backend mcrt computations - 1. |
| mem_affinity | string “on”|“off” |
”” (empty) | Specify mem_affinity option (See here for more details). |
| numMachines | int |
-1 (default value does not work. You should always define numMachines) | Set the total number of backend mcrt computations. The number should be 1 or bigger. |
| packTilePrecision | string auto32 | auto16 | full32 | full16 |
auto16 | The packTile codec is used in order to transfer image data between computations and clients. This command sets the packTile codec’s precision mode (see below). |
| renderMode | string “realtime” |
”” (empty) | This is an experimental command. If you set “realtime” renderMode, the backend mcrt computation changes internal operation to realtime rendering mode. If you don’t set this command, backend mcrt computation uses “progressive” render mode for single machine computation and uses “timebased checkpoint” mode for multi-machine configuration. |
| scene | string (scene-filename.rdl{a|b}) |
”” (empty) | Backend mcrt computation reads this scene data just after booting if defined. |
| socket_affinity | string ”<socketIdString>“ |
”” (empty) | Specify socket_affinity option (See here for more details). |
More info on packTilePrecision options:
We have 2 stages of image generation. coarse pass stage and fine pass stage.
- auto32 : automatically switches UC8 (8bit int) and H16 (half 16bit float) depending on the data for the coarse pass stage, and uses F32 (full 32bit float) for the fine pass stage.
- auto16 : automatically switches UC8 (8bit int) and H16 (half 16bit float) depending on the data for the coarse pass stage. and uses H16 (half 16bit float) for the fine pass stage.
- full32 : always uses F32 (full 32bit float) for all stages
- full16 : always uses H16 (half 16bit float) for all stages
This packTile precision control has a big impact on the message traffic volume. A smaller message size is always good for performance. auto16 always can generate the smallest possible messages and the best from a performance standpoint. However, if you need to get exact full precision of float data on the client, auto32 or full32 would be a practical choice.
Merge computation
| attribute | type | default | description |
|---|---|---|---|
| fps | float |
12.0 | set merged image update send to client FPS. |
| initialCredit | int |
-1 | set initial credit rate for arras message passing layer. If rate is >= 0 credit rate control will be enabled otherwise it is inactive. |
| maxThreads | int |
all threads of running hosts based on the CPU cores | set the total number of threads. |
| numMachines | int |
0 (default value does not work. You should always define numMachines) | set the total number of backend mcrt computation. The number should be 1 or greater. |
| partialMergeRefreshInterval | float |
0.25 (sec) | In order to minimize output data bandwidth, backend merge computation try to merge images by partial small areas and try to cover the entire image area by multiple merge operations. This command set the entire image area cover frequency by second. If you set a small number, client-side image updates smoother but output bandwidth gets bigger and network bandwidth might be a bottleneck in some cases. |
| packTilePrecision | string auto32 | auto16 | full32 | full16 |
auto16 | PackTile codec is used in order to transfer image data between computations and clients. This commands set packTile codecs precision mode. |
| sendCredit | bool |
false | Need to be set to true if you use credit messages. |
More info on packTilePrecision options:
We have 2 stages in image generation. coarse pass stage and fine pass stage.
- auto32 : automatically switches UC8 (8bit int) and H16 (half 16bit float) depending on the data for the coarse pass stage, and uses F32 (full 32bit float) for the fine pass stage.
- auto16 : automatically switches UC8 (8bit int) and H16 (half 16bit float) depending on the data for the coarse pass stage. and uses H16 (half 16bit float) for the fine pass stage.
- full32 : always uses F32 (full 32bit float) for all stages
- full16 : always uses H16 (half 16bit float) for all stages
This packTile precision control is a crucial and big impact on the message traffic volume. A smaller message size is always good for performance. auto16 always can generate the smallest possible messages and the best from a performance standpoint. However, if you need to get exact full precision of float data on the client, auto32 or full32 would be a practical choice.