Optimizing the ALab Scene
The page notes ways to optimize rendering for the ALab Scene. It can serve as a useful example for optimizing scenes in general for rendering. In particular, pay attention to:
Texture Cache Size Considerations
Selecting the proper texture cache size is crucial for efficient rendering of especially texture-heavy scenes like the ALab Scene. The best configuration will be dependant on the scene itself as well as the machine environment. A quick general solution to find a good texture cache size for a general moonray run is documented here.
This is a rendered result image of ALab, v2.0.1 without denoising

The texture cache size setting has a large impact on the efficiency of rendering especially texture-heavy scenes like ALab. What follows are the results of tests profiling the results of MCRT time (not including the RenderPrep time) for various different texture cache sizes on the ALab scene.
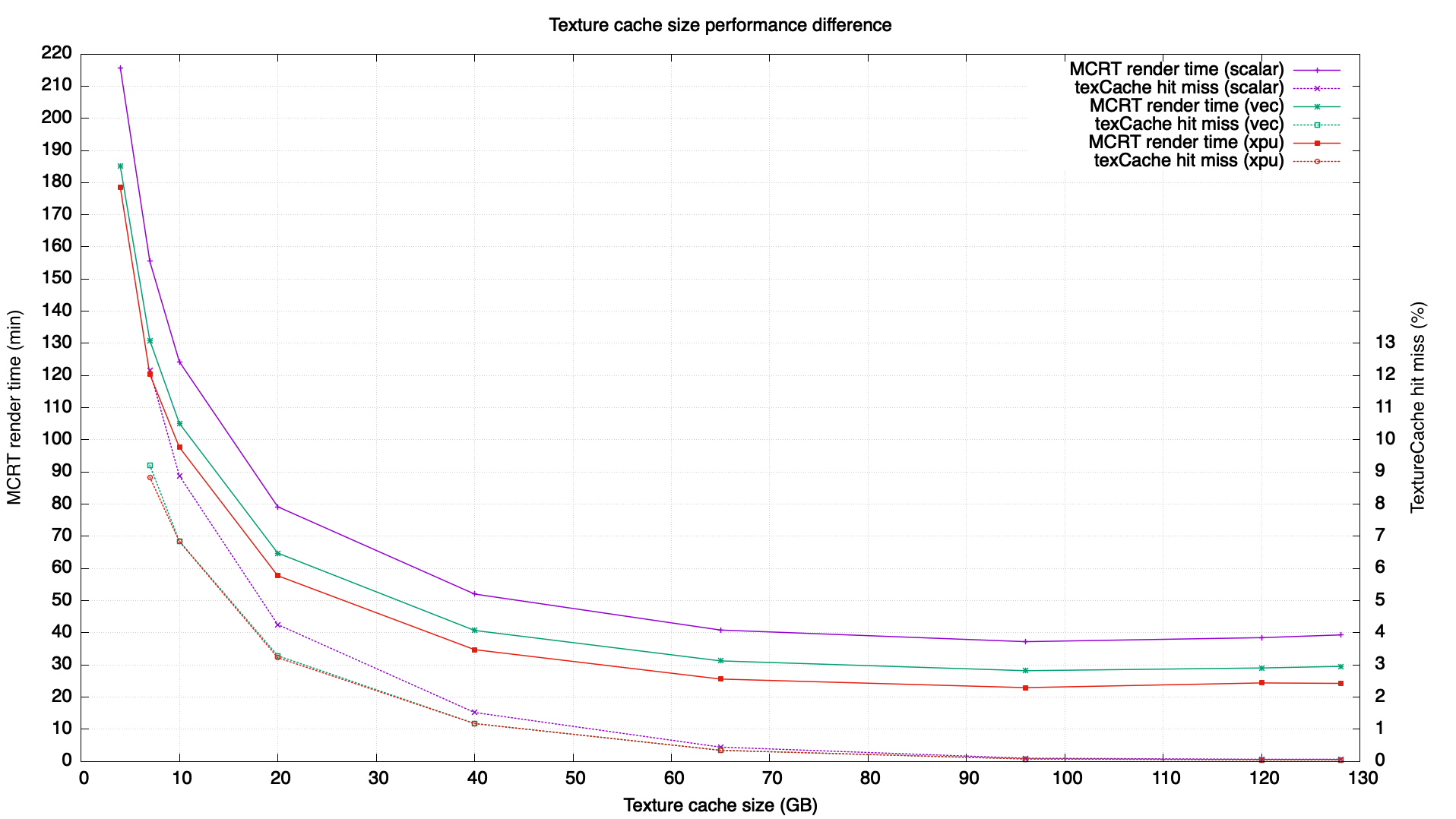
All tests are using the vanilla ALab v2.0.1 scene with no optimization of the scene itself) and with 4K high resolution textures and baked geometry. The Linux kernel cache was warmed by a preliminary test render. All tests were rendered 3 times and the results were averaged.
All sceneVariable settings are the default, except for image size and uniform sampling related parameters.
SceneVariables {
["image_width"] = 1920,
["image_height"] = 1080,
["sampling mode"] = 0,
["pixel samples"] = 8,
["motion_steps"] = { -0.25, 0.25},
-- ["texture_cache_size"] = 4096 -- 4G
-- ["texture_cache_size"] = 7168 -- 7G
-- ["texture_cache_size"] = 10240 -- 10G
-- ["texture_cache_size"] = 20480 -- 20G
-- ["texture_cache_size"] = 40960 -- 40G
-- ["texture_cache_size"] = 66560 -- 65G
["texture_cache_size"] = 98304 -- 96G
-- ["texture_cache_size"] = 122880 -- 120G
-- ["texture_cache_size"] = 131072 -- 128G
}
The tests were run on the following machine specs:
CPU : Intel(R) Xeon(R) Gold 6240R CPU @ 2.40GHz
Physical CPU : 2
CPU cores : 24
Total cores : 48 (HyperThread OFF)
Memory : 187 GByte (However, test redner was done around 124GByte of free memory)
GPU : Nvidia Quadro RTX 6000
These tests were based on OpenImageIO v2.3.20.
Note that the 4GByte (actually, default is 3.91GByte) texture cache render run did not show the main cache hit-miss ratio in the log and is not plotted on the graph.
In the results the overall render performance using a 96GByte texture cache size would be the ideal configuration for this scene in this environment. More than 96GByte is basically fine but it does slightly slow down the rendering, likely due to an overly large texture cache swapping out some portion of the BVH and sceneContext memory at runtime, which makes some small impact on the final efficiency, and as a result a slower render.
XPU performance is consistently better than scalar and its ratio is 1.20x ~ 1.62x more performant. Vector performance is also consistently better than scalar and its ratio is 1.16x ~ 1.33x more performant. MoonRay’s Vector/XPU architecture is very useful for texture-heavy scenes and maximizes the memory access coherency.
This is a breakdown of runtime timing by profile_viewer for the XPU runs.
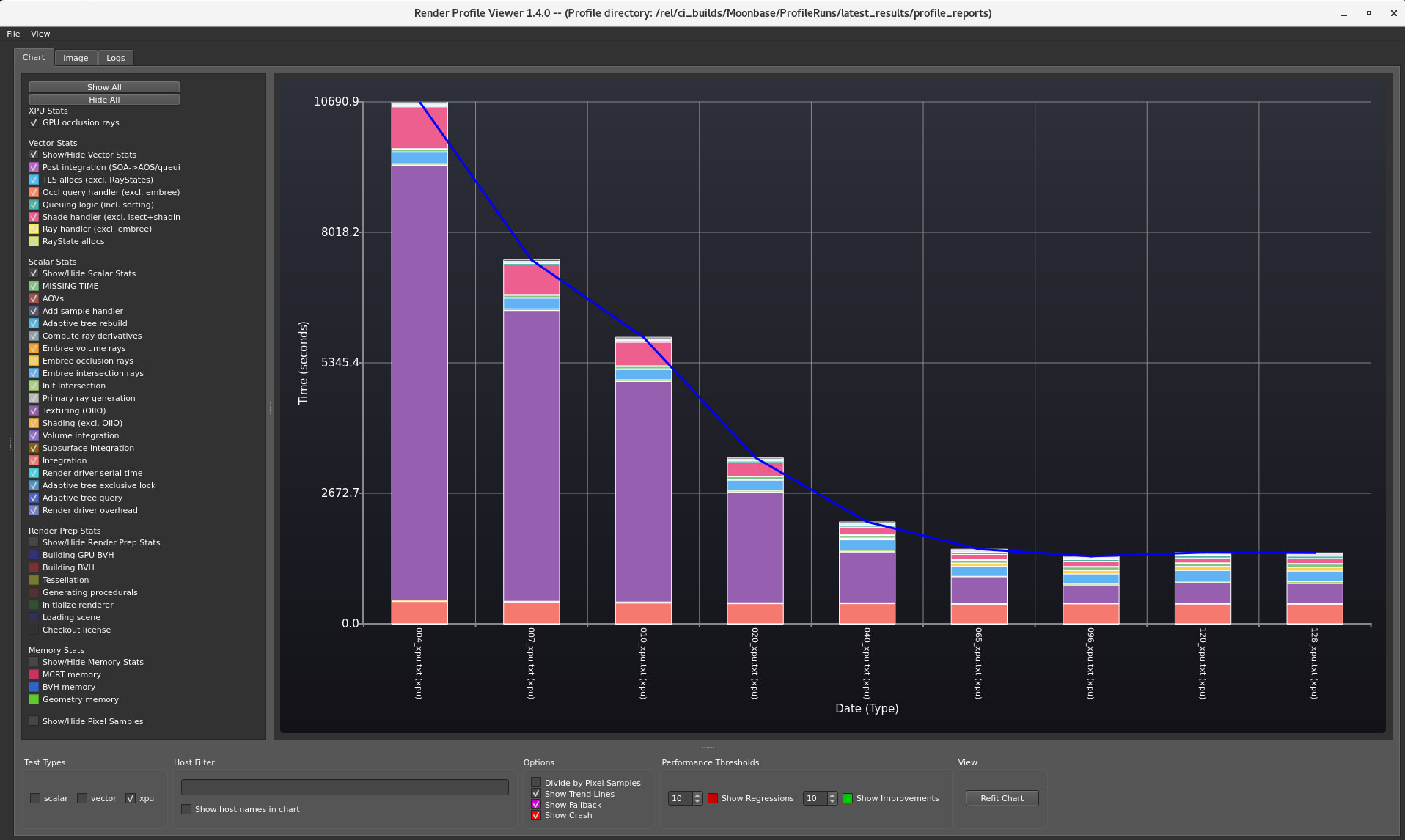
As can be seen, the texturing time is dominant when the texture cache size is small. Also, shader handler time is directly related to the texturing time and it is increasing as the texturing time increases. Performance is improved when texture sampling cost is lowered by increasing the texture cache size.
Quality Control
The following sceneVariable settings are a good starting point for low, medium, and high-quality renders for uniform / adaptive sampling based on several recent DreamWorks Animation productions. Technically, the ideal parameter combination will likely be different from scene to scene, but these settings should represent reasonable defaults.
-- low quality uniform sampling
SceneVariables {
-- pixel sampling settings
["sampling_mode"] = "uniform",
["pixel_samples"] = 3,
-- sampling settings
["bsdf_samples"] = 2,
["light_samples"] = 2,
["bssrdf_samples"] = 2,
-- depth settings
["max_depth"] = 10,
["max_diffuse_depth"] = 6,
["max_glossy_depth"] = 6,
["max_mirror_depth"] = 6,
["max_hair_depth"] = 10,
["max_presence_depth"] = 16,
["max_subsurface_per_path"] = 1,
["max_volume_depth"] = 1,
-- other
["russian_roulette_threshold"] = 0.018,
["sample_clamping_depth"] = 1,
["sample_clamping_value"] = 10,
["roughness_clamping_factor"] = 0,
}
-- medium quality uniform sampling
SceneVariables {
-- pixel sampling settings
["sampling_mode"] = "uniform",
["pixel_samples"] = 6,
-- sampling settings
["bsdf_samples"] = 2,
["light_samples"] = 2,
["bssrdf_samples"] = 3,
-- depth settings
["max_depth"] = 10,
["max_diffuse_depth"] = 6,
["max_glossy_depth"] = 6,
["max_mirror_depth"] = 6,
["max_hair_depth"] = 10,
["max_presence_depth"] = 16,
["max_subsurface_per_path"] = 1,
["max_volume_depth"] = 1,
-- other
["russian_roulette_threshold"] = 0.018,
["sample_clamping_depth"] = 1,
["sample_clamping_value"] = 10,
["roughness_clamping_factor"] = 0,
}
-- high quality uniform sampling
SceneVariables {
-- pixel sampling settings
["sampling_mode"] = "uniform",
["pixel_samples"] = 10,
-- sampling settings
["bsdf_samples"] = 2,
["light_samples"] = 2,
["bssrdf_samples"] = 3,
-- depth settings
["max_depth"] = 10,
["max_diffuse_depth"] = 6,
["max_glossy_depth"] = 6,
["max_mirror_depth"] = 6,
["max_hair_depth"] = 10,
["max_presence_depth"] = 16,
["max_subsurface_per_path"] = 1,
["max_volume_depth"] = 1,
-- other
["russian_roulette_threshold"] = 0.018,
["sample_clamping_depth"] = 1,
["sample_clamping_value"] = 10,
["roughness_clamping_factor"] = 0,
}
-- low quality adaptive sampling
SceneVariables {
-- pixel sampling settings
["sampling_mode"] = "adaptive",
["min_adaptive_samples"] = 4, -- 2x2
["max_adaptive_samples"] = 16, -- 4x4
["target_adaptive_error"] = 10,
-- sampling settings
["bsdf_samples"] = 2,
["light_samples"] = 2,
["bssrdf_samples"] = 2,
-- depth settings
["max_depth"] = 10,
["max_diffuse_depth"] = 6,
["max_glossy_depth"] = 6,
["max_mirror_depth"] = 6,
["max_hair_depth"] = 10,
["max_presence_depth"] = 16,
["max_subsurface_per_path"] = 1,
["max_volume_depth"] = 1,
-- other
["russian_roulette_threshold"] = 0.018,
["sample_clamping_depth"] = 1,
["sample_clamping_value"] = 10,
["roughness_clamping_factor"] = 0,
}
-- medium quality adaptive sampling
SceneVariables {
-- pixel sampling settings
["sampling_mode"] = "adaptive",
["min_adaptive_samples"] = 16, -- 4x4
["max_adaptive_samples"] = 64, -- 8x8
["target_adaptive_error"] = 7.5,
-- sampling settings
["bsdf_samples"] = 2,
["light_samples"] = 2,
["bssrdf_samples"] = 3,
-- depth settings
["max_depth"] = 10,
["max_diffuse_depth"] = 6,
["max_glossy_depth"] = 6,
["max_mirror_depth"] = 6,
["max_hair_depth"] = 10,
["max_presence_depth"] = 16,
["max_subsurface_per_path"] = 1,
["max_volume_depth"] = 1,
-- other
["russian_roulette_threshold"] = 0.018,
["sample_clamping_depth"] = 1,
["sample_clamping_value"] = 10,
["roughness_clamping_factor"] = 0,
}
-- high quality adaptive sampling
SceneVariables {
-- pixel sampling settings
["sampling_mode"] = "adaptive",
["min_adaptive_samples"] = 100, -- 10x10
["max_adaptive_samples"] = 256, -- 16x16
["target_adaptive_error"] = 3,
-- sampling settings
["bsdf_samples"] = 2,
["light_samples"] = 2,
["bssrdf_samples"] = 3,
-- depth settings
["max_depth"] = 10,
["max_diffuse_depth"] = 6,
["max_glossy_depth"] = 6,
["max_mirror_depth"] = 6,
["max_hair_depth"] = 10,
["max_presence_depth"] = 16,
["max_subsurface_per_path"] = 1,
["max_volume_depth"] = 1,
-- other
["russian_roulette_threshold"] = 0.018,
["sample_clamping_depth"] = 1,
["sample_clamping_value"] = 10,
["roughness_clamping_factor"] = 0,
}
Image quality difference
Low quality uniform sampling

Medium quality uniform sampling

High quality uniform sampling

Low quality adaptive sampling

Medium quality adaptive sampling
[ ]https://docs.openmoonray.org/assets/images/user-reference/alab/out_096mdAdptXpu0.png)
]https://docs.openmoonray.org/assets/images/user-reference/alab/out_096mdAdptXpu0.png)
High quality adaptive sampling

Render Time Comparison
The following tests show what is the difference in terms of quality and render time for each quality setting.
The test were run on the following machine specs:
CPU : Intel(R) Xeon(R) Gold 6240R CPU @ 2.40GHz
Physical CPU : 2
CPU cores : 24
Total cores : 48 (HyperThread OFF)
Memory : 187 GByte (However, test render was done with around 124GByte of free memory)
GPU : Nvidia Quadro RTX 6000
Texture cache size is 96GByte. Ran 4 times and ignored 1st run (cache warm-up) then averaged from 2nd to 4th.
Uniform sampling : MCRT phase (sec)
| quality | scalar | vector | xpu |
|---|---|---|---|
| low | 604.35 | 486.47 | 435.95 |
| medium | 1973.41 | 1515.78 | 1285.10 |
| high | 5174.14 | 3940.35 | 3268.74 |
Adaptive sampling : MCRT phase (sec)
| quality | scalar | vector | xpu |
|---|---|---|---|
| low | 1021.93 | 845.62 | 760.17 |
| medium | 3438.34 | 2867.37 | 2442.24 |
| high | 13132.25 | 10912.51 | 9286.71 |